غوغل تُحفّز خوارزميات الذكاء الاصطناعي بنظام للمُكافآت
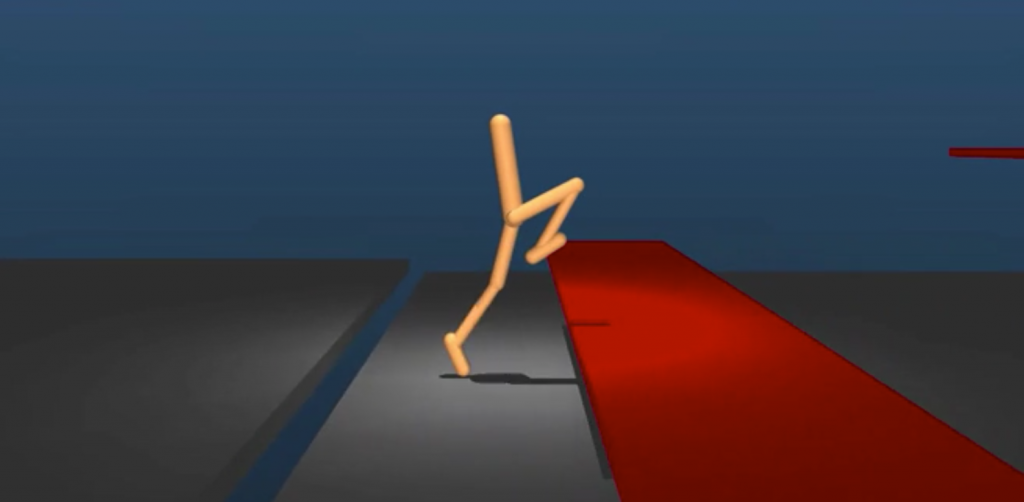
نشرت شركة DeepMind، التي تعمل تحت مظّلة غوغل في مجال الذكاء الاصطناعي AI، أبحاث جديدة حول تعليم الآلة عن طريق استخدام نظام تعزيز التعلّم Reinforcement learning، وهو نظام قائم على المُكافآت بشكل أساسي.
وطوّرت الشركة خوارزميات تسمح للآلة بتجاوز العقبات في مُحاكي لرياضة الباركور، بحيث تقوم الآلة برصد الحواجز والعوائق لتقوم بالقفز فوقها، وكلّما كان الزمن اللازم لإنهاء المرحلة أقل، كُلّما كانت المُكافآت أعلى. وبالمثل، فإن الاصطدام بالحواجز سيُضيف مُخالفات إلى رصيد الآلة.
وبشكل عام، فإن البيئة التطويرية تقوم على نقل المُجسّم من نقطة أ إلى نقطة ب عن طريق الخوارزميات فقط، أي أن كل شيء يجري عن طريق الذكاء الاصطناعي دون تدخّل الإنسان.
وتعكس هذه الأبحاث أن الآلة أصبحت قادرة على رصد العوائق قبل الوصول إليها لاتّخاذ القرار المناسب عند الوصول إليها. ومثل تلك الاستخدامات يُمكن أن تكون مفيدة في أنظمة القيادة الذاتية على سبيل المثال، بحيث يقوم النظام برصد أي شيء قبل فترة من الزمن لاتّخاذ القرار بسرعة أكبر.
Agents having fun in Parkour! Cool paper from colleagues at DeepMind https://t.co/X0PwKXrQ2M pic.twitter.com/yMT6XCNv45
— Oriol Vinyals (@OriolVinyalsML) July 10, 2017









